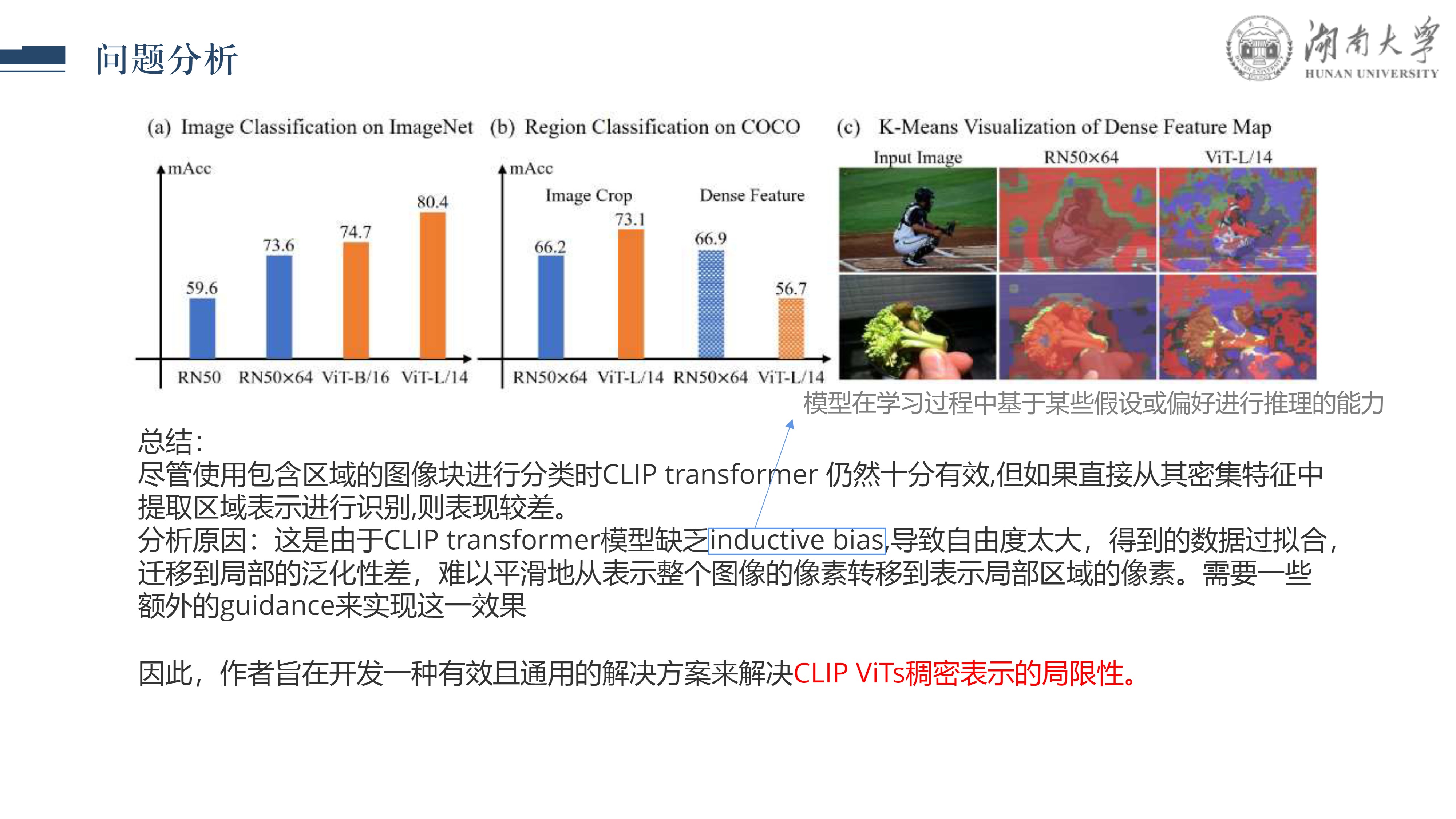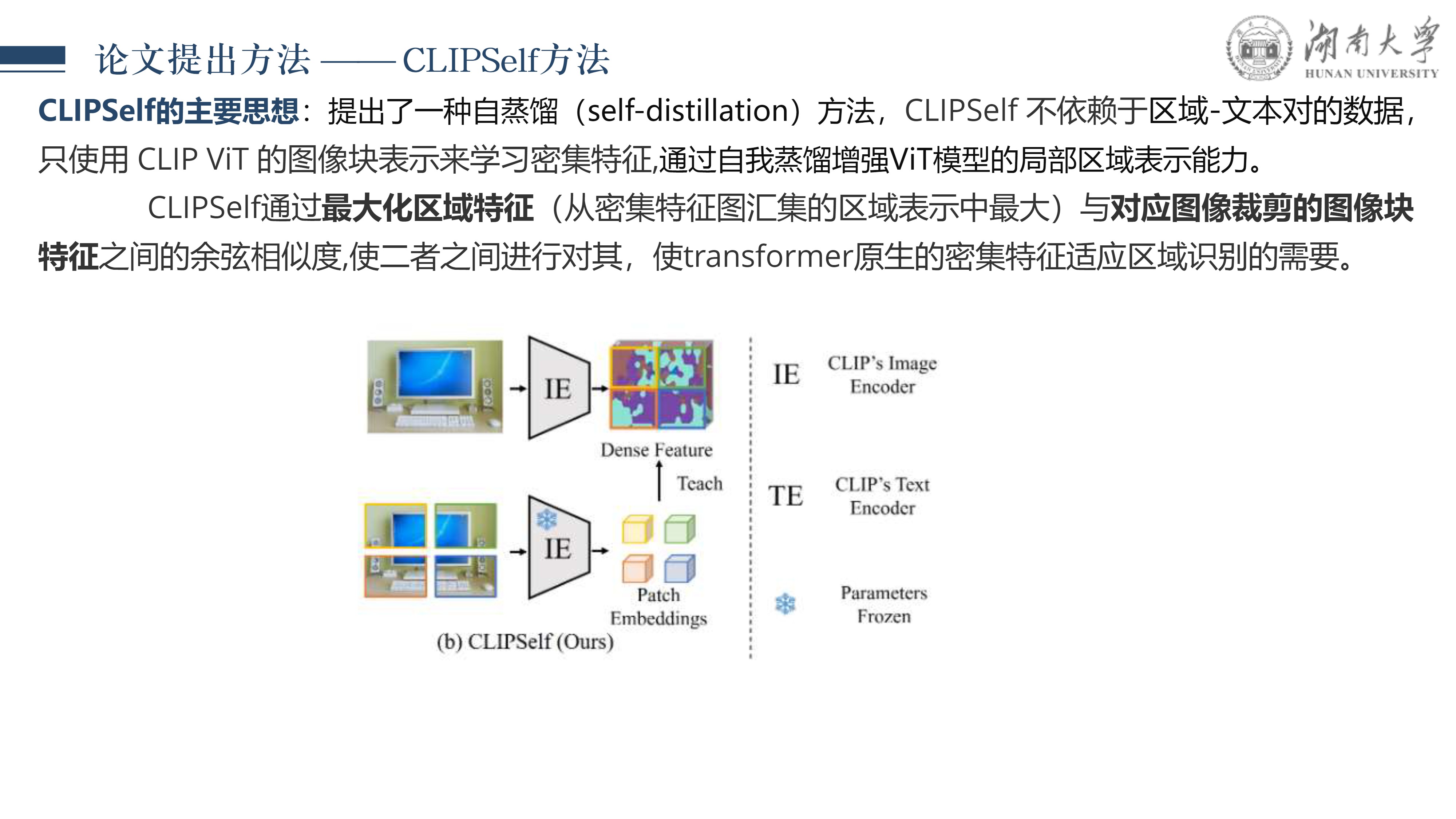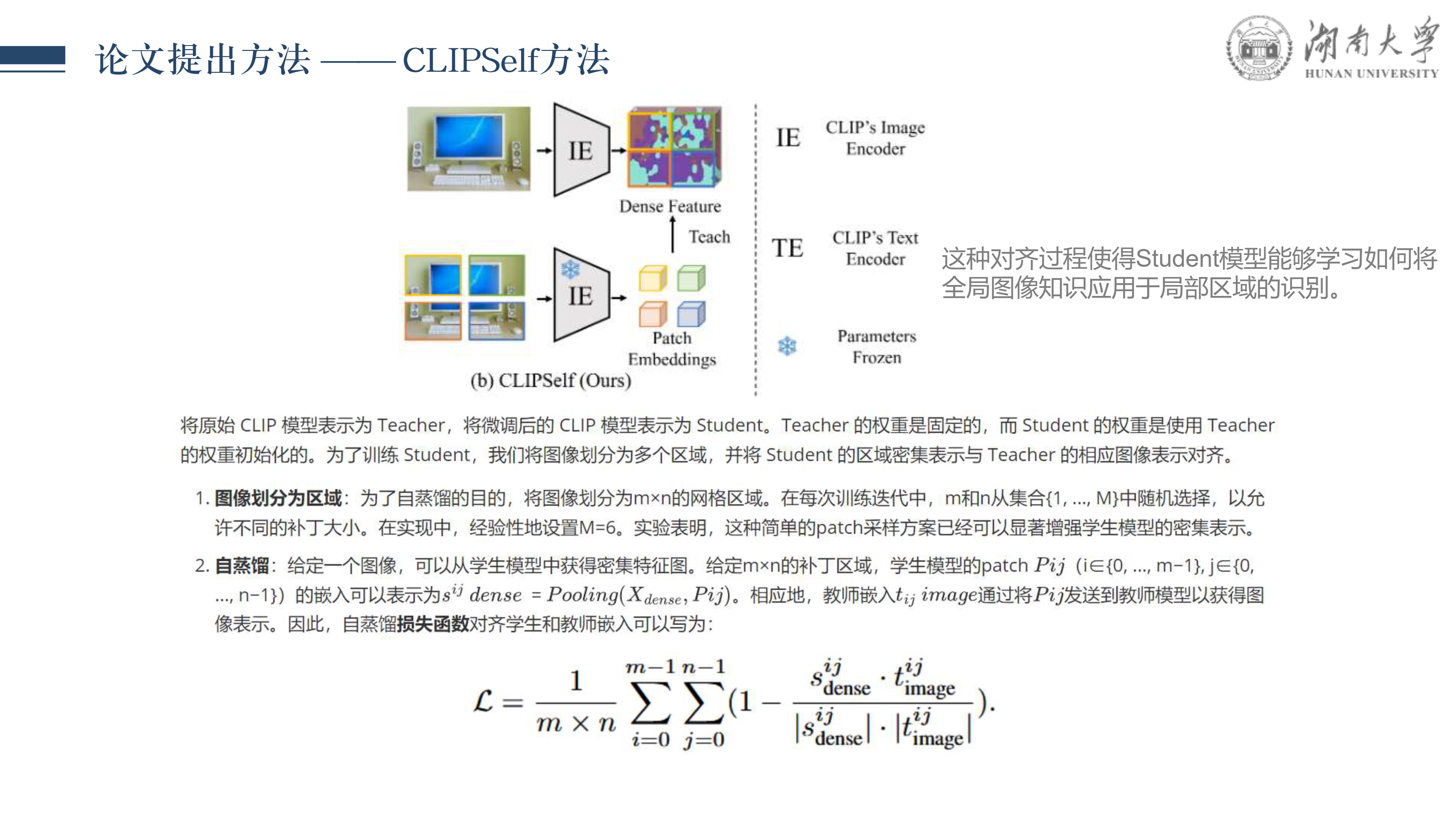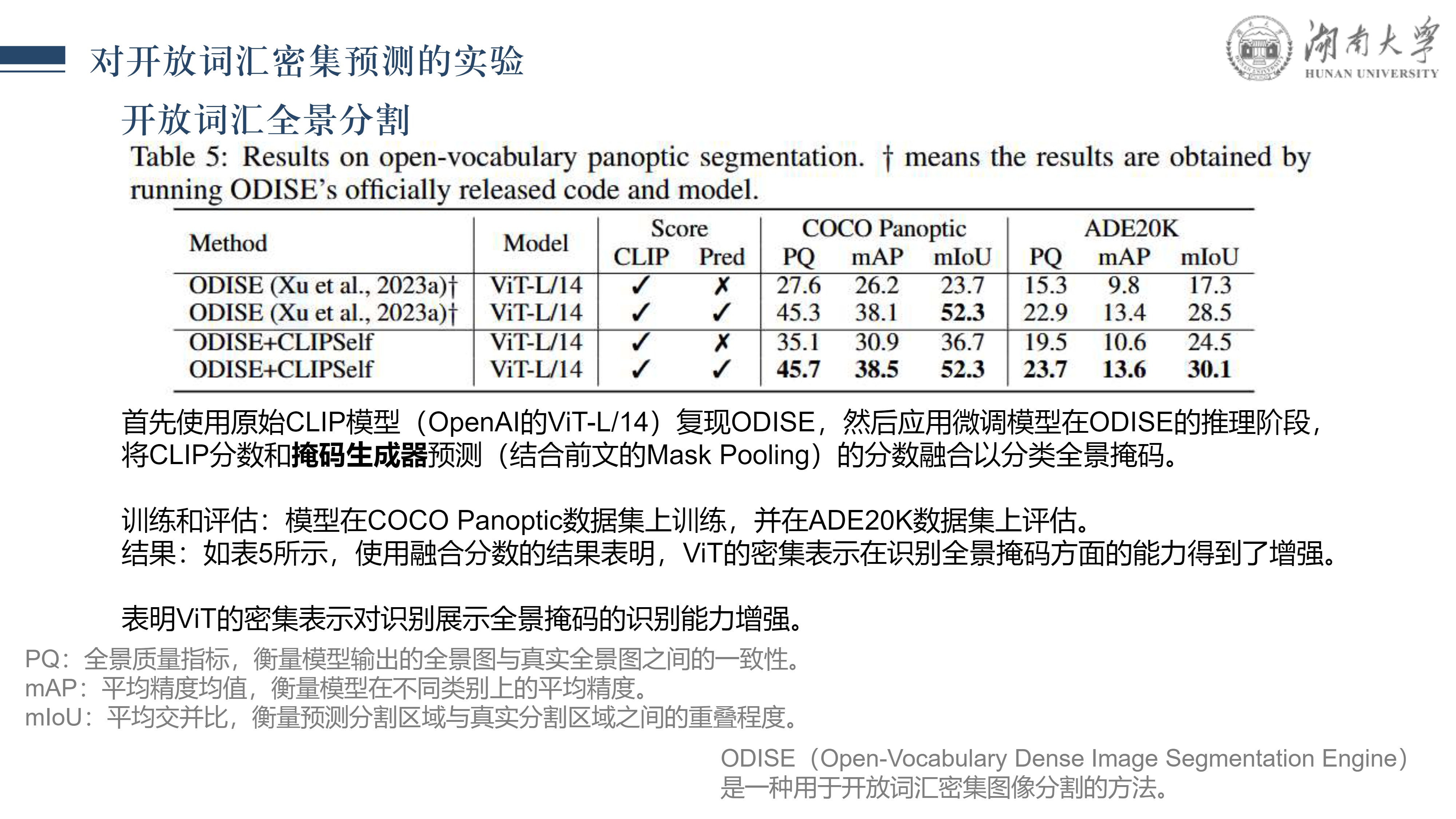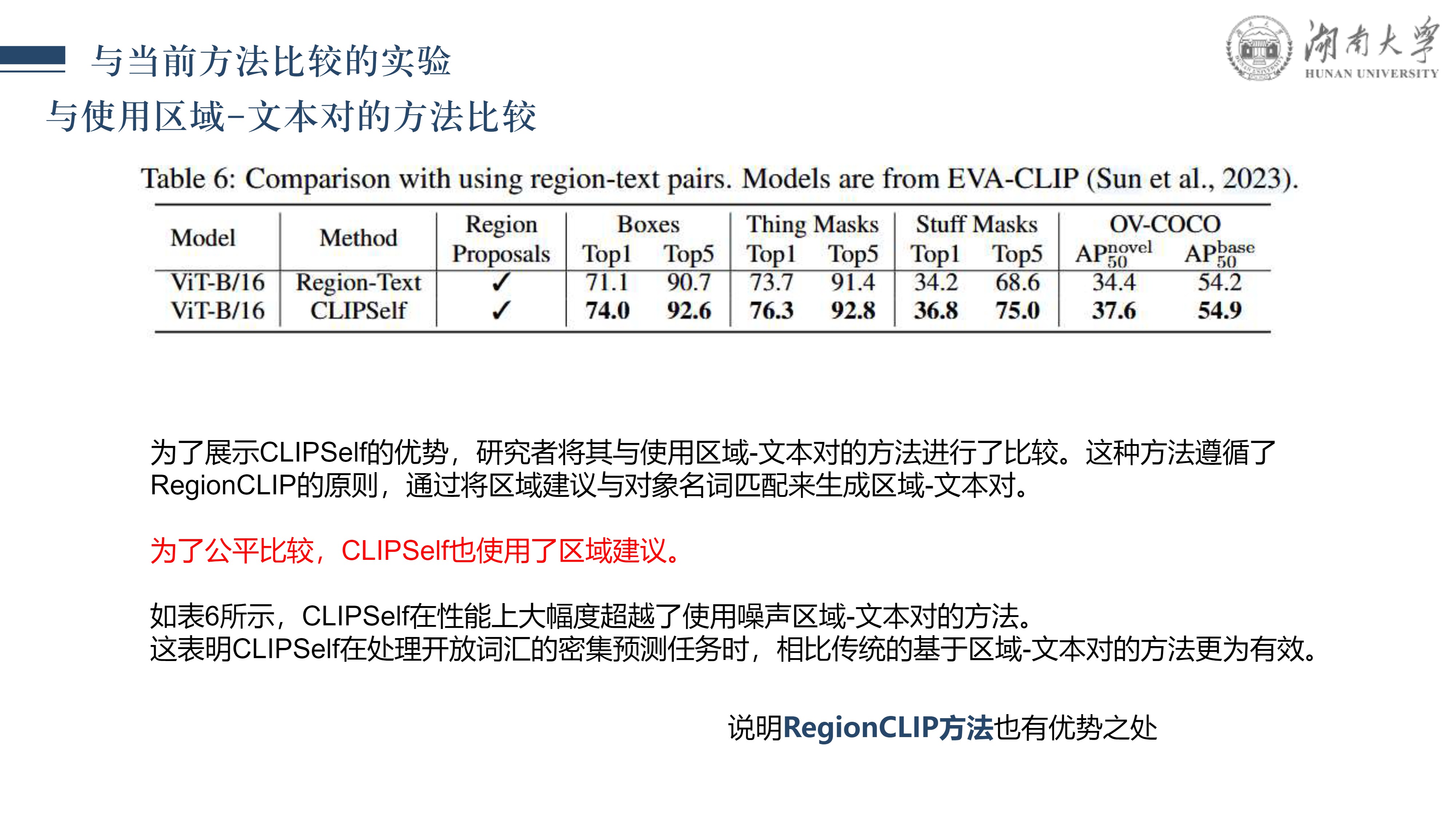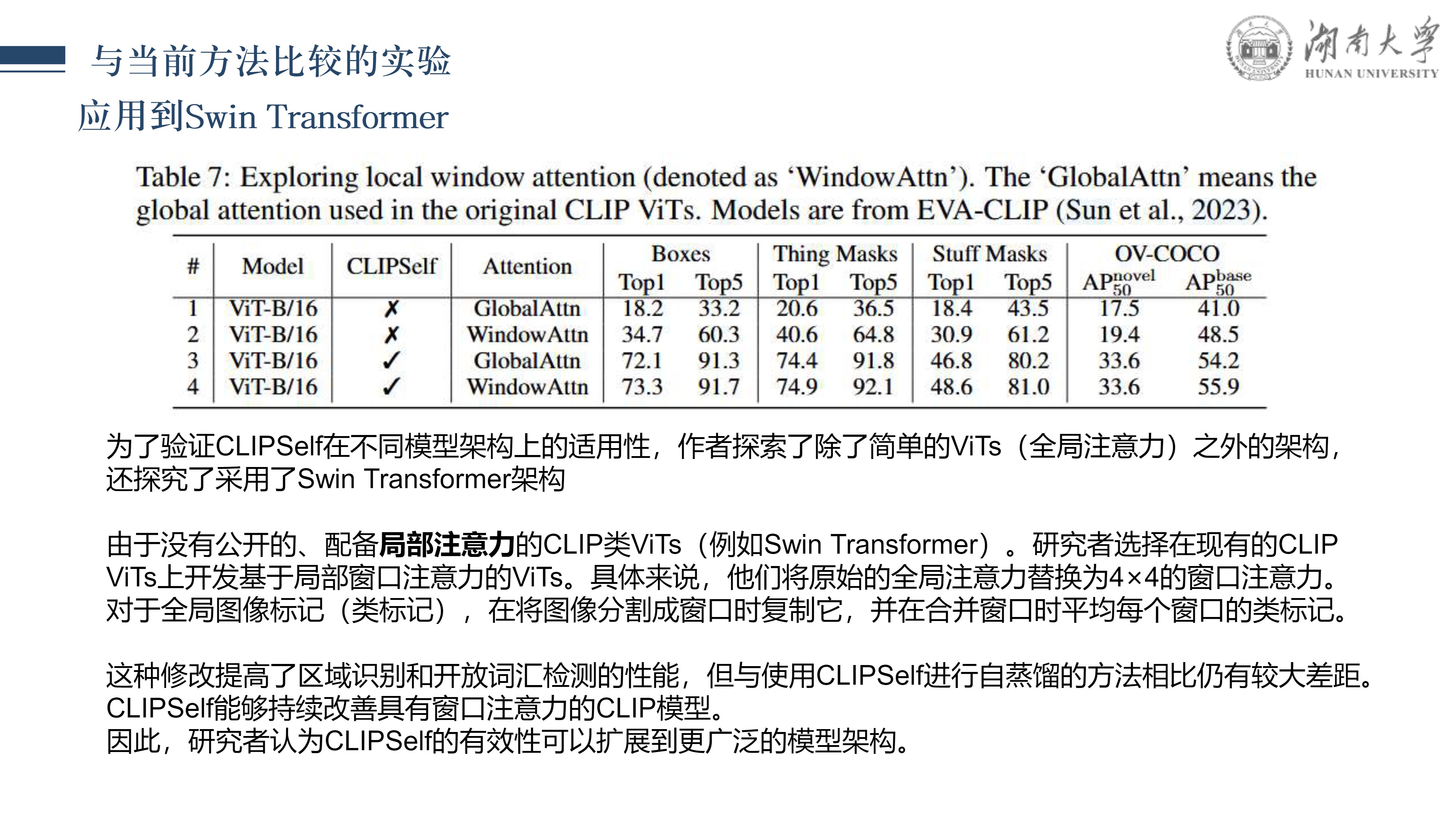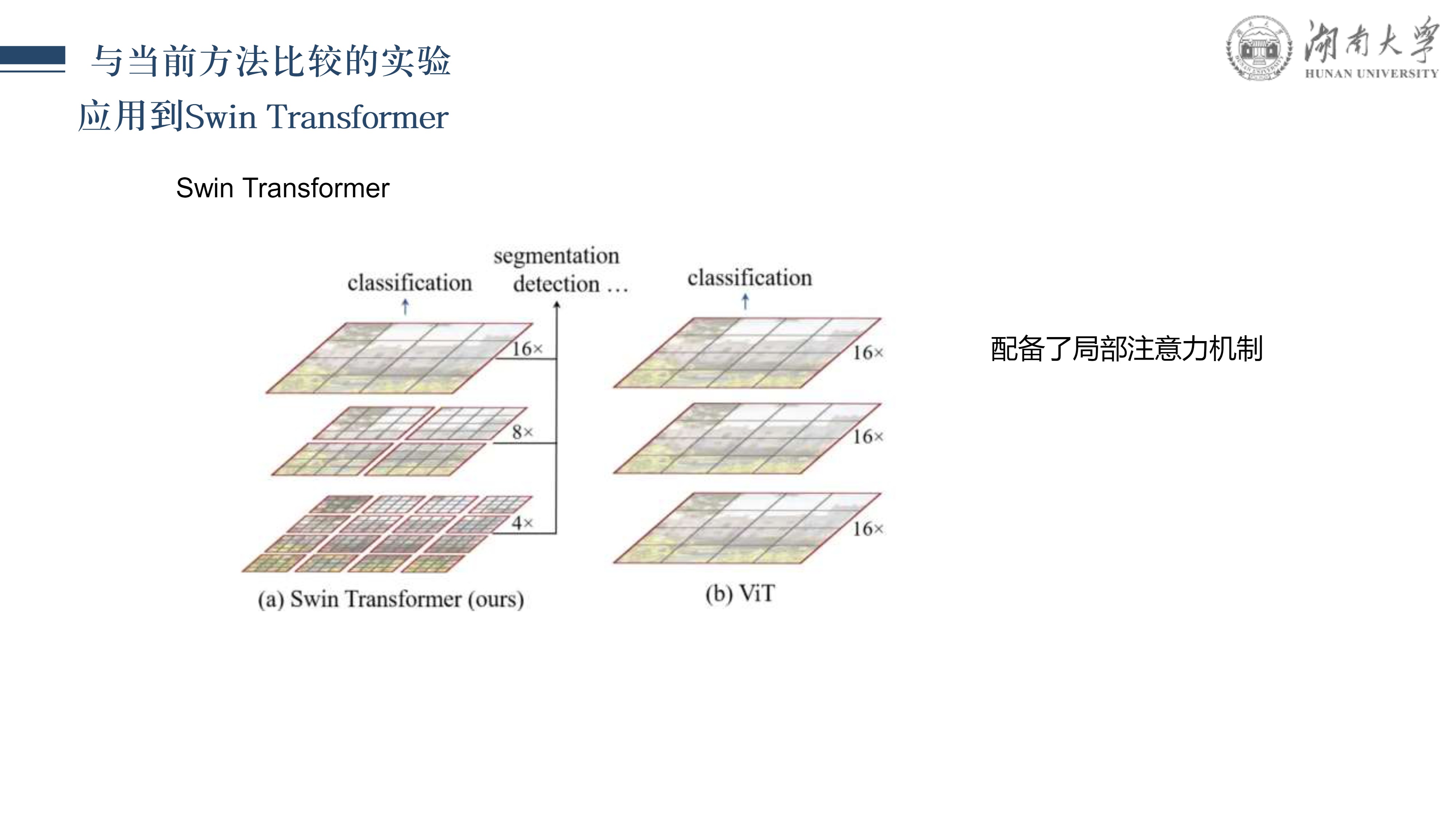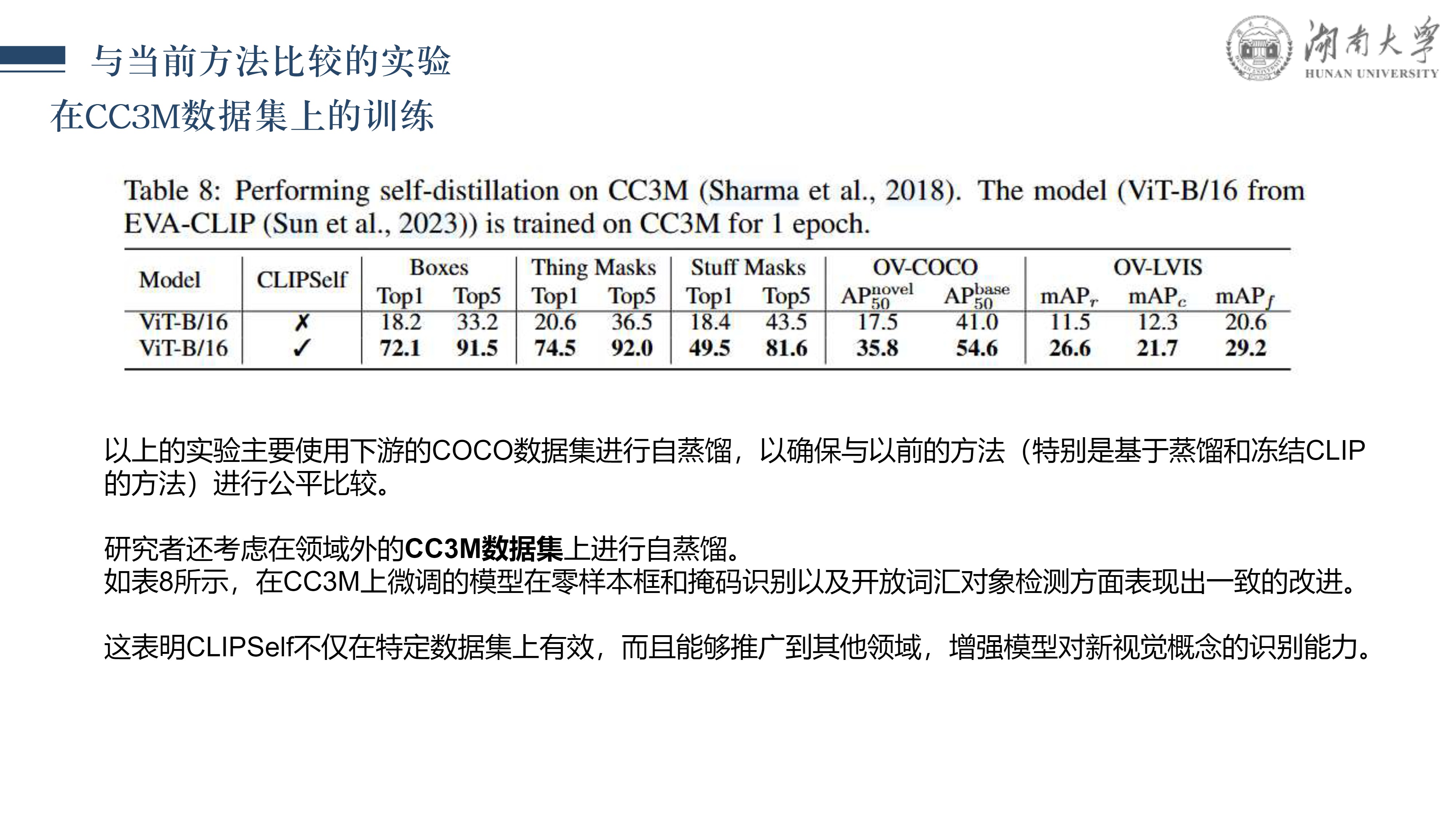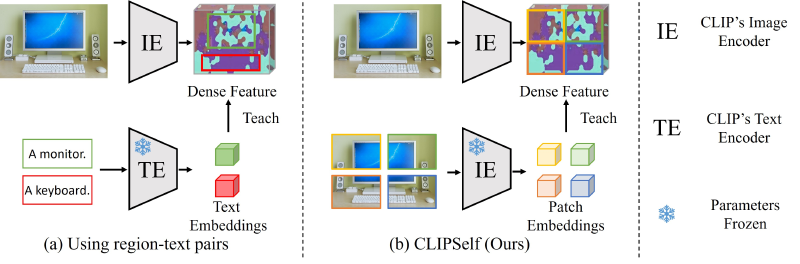
CLIPSelf: 视觉Transformer自蒸馏用于开放词汇的密集预测
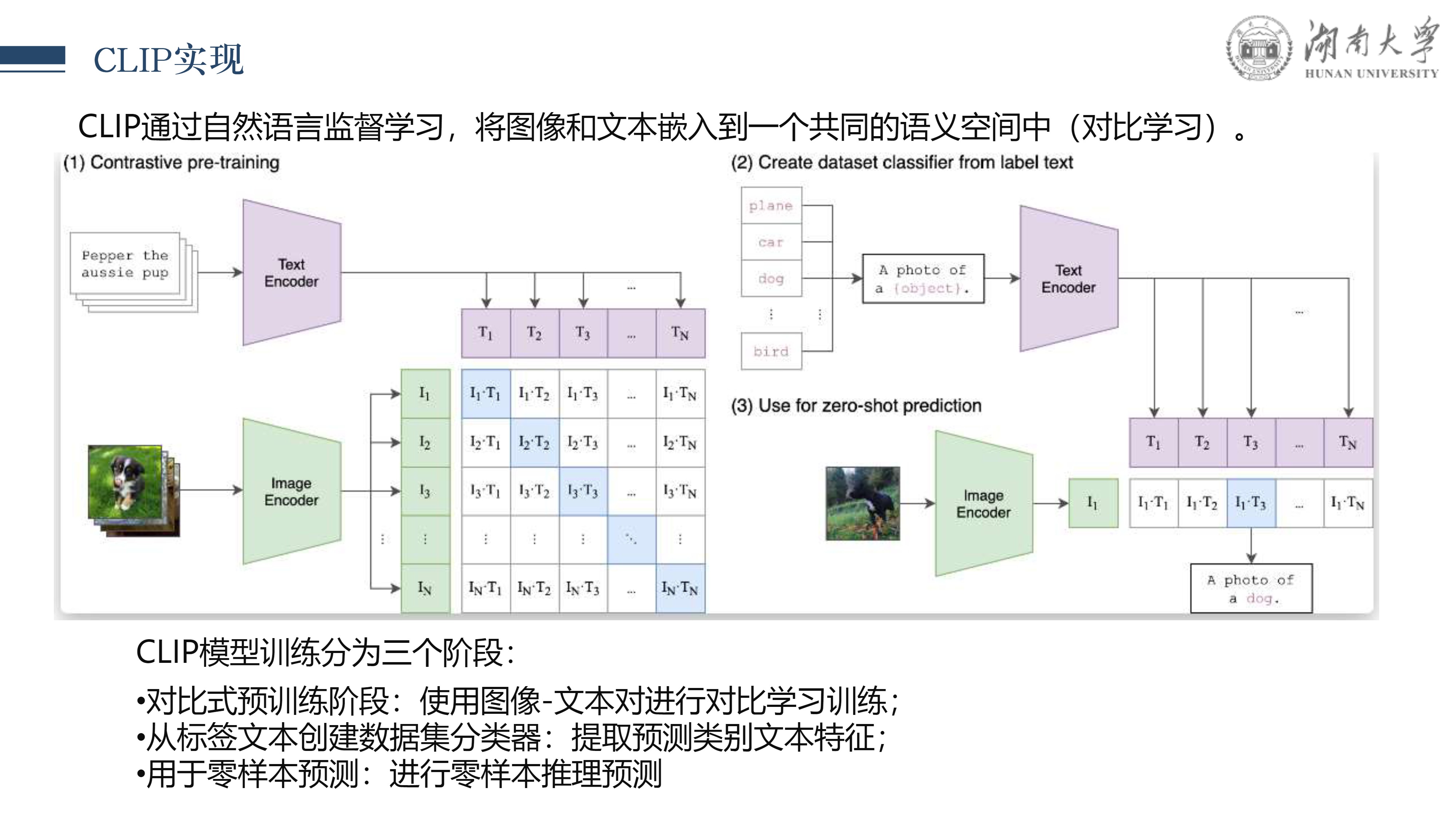
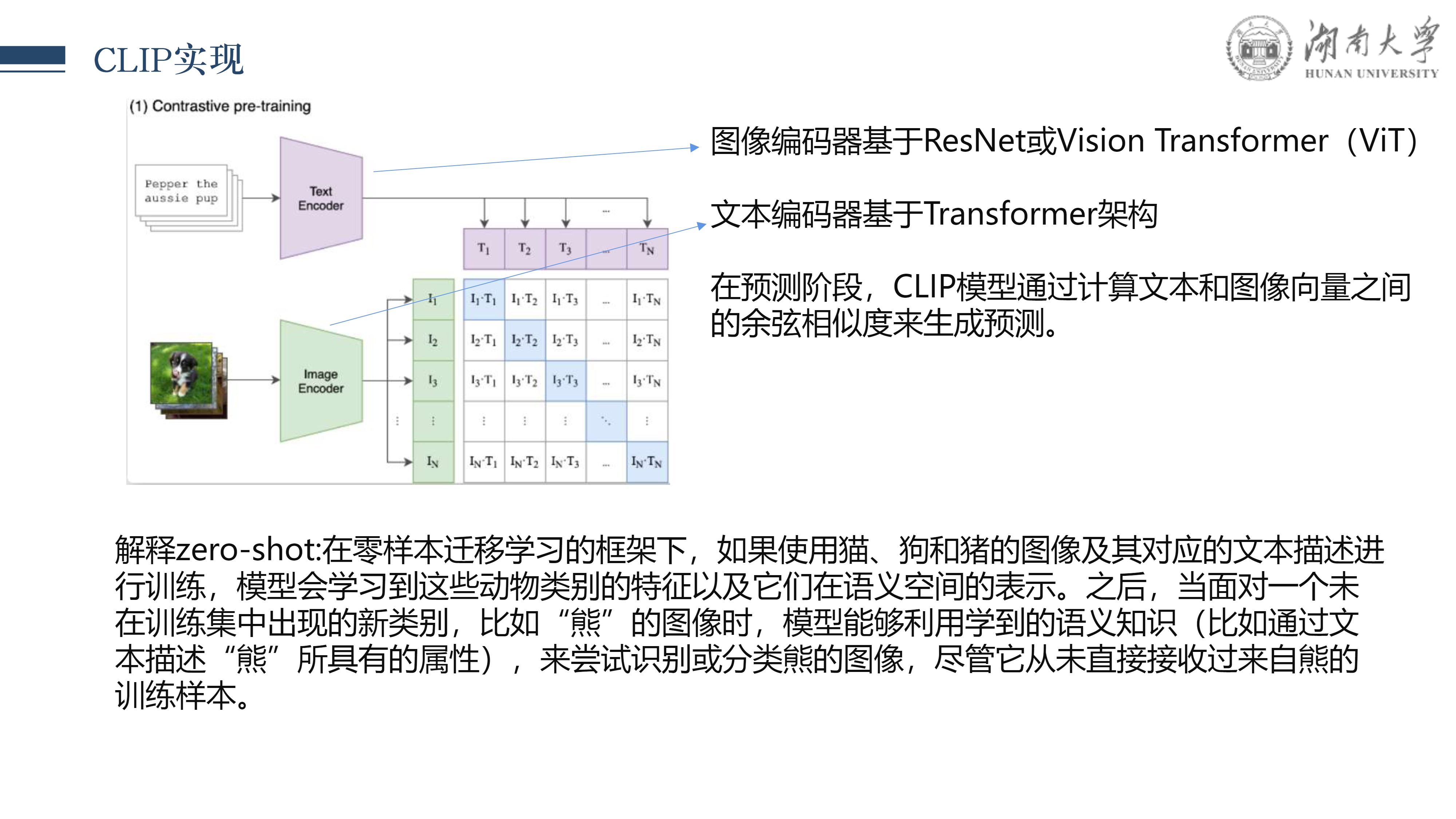
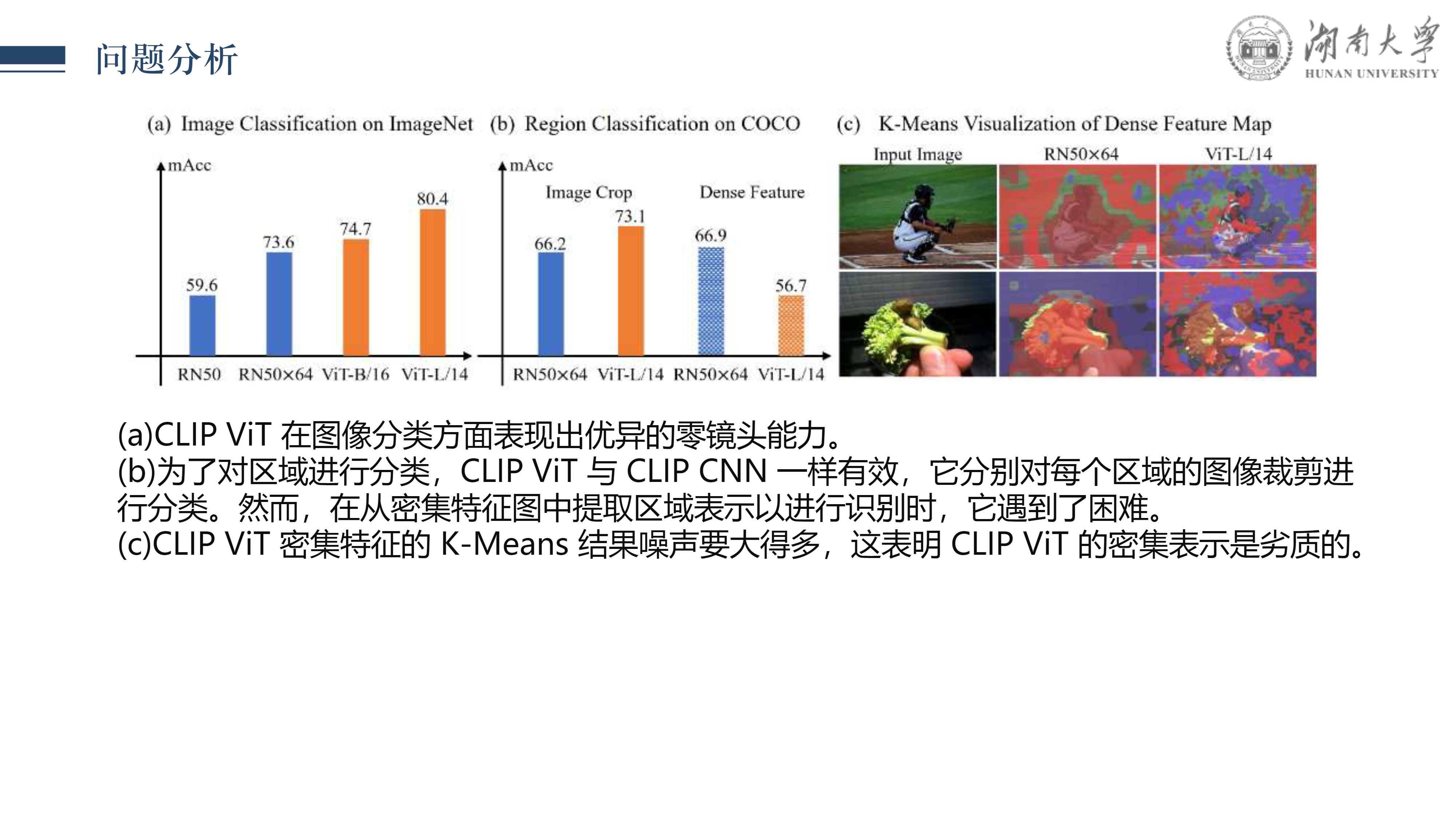
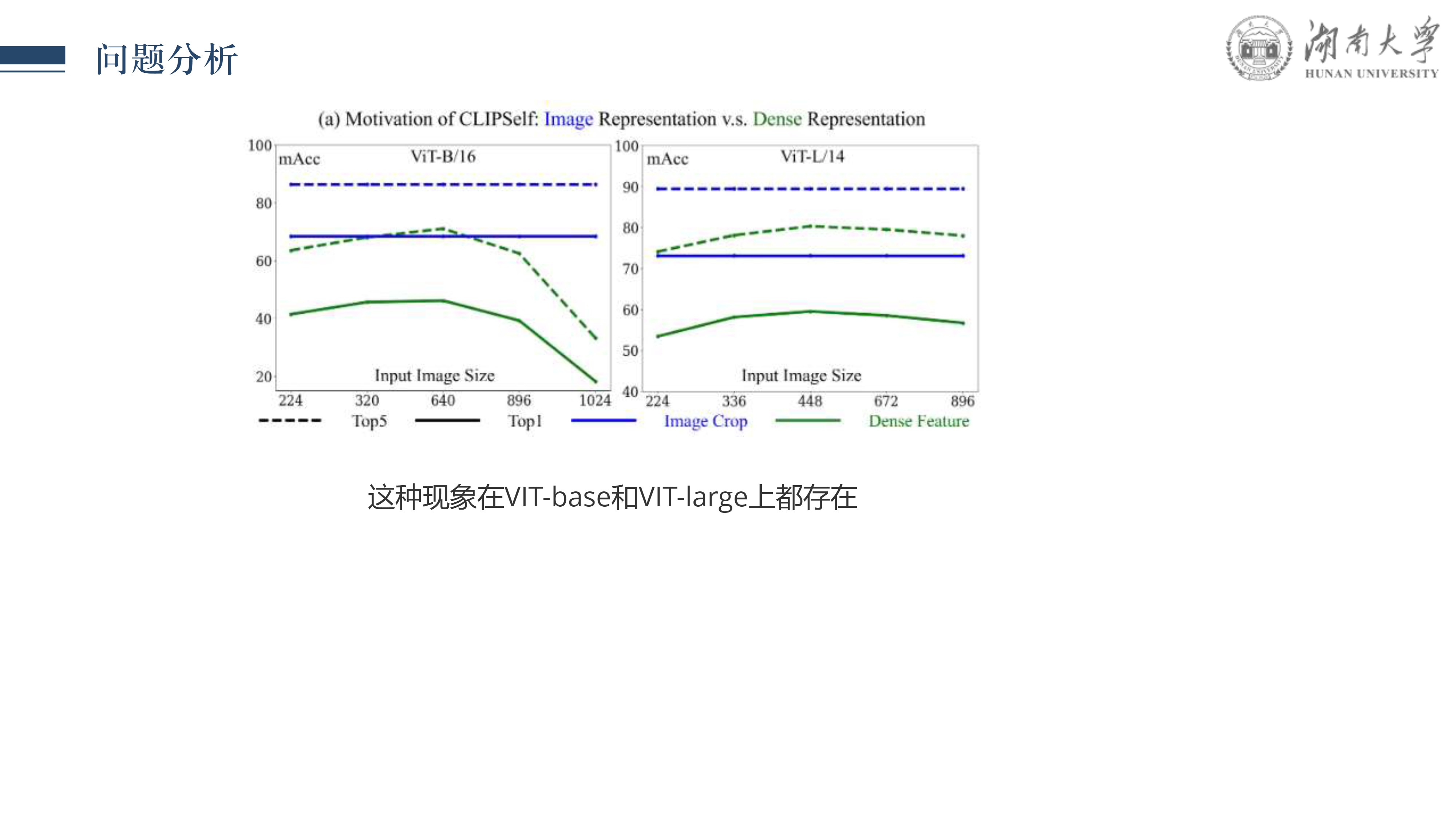
本文我是对 CLIPSelf 论文的详细解读,该论文提出了一种创新的视觉 Transformer 自蒸馏方法,旨在解决开放词汇的密集预测任务。 CLIP (Contrastive Language-Image Pre-training) 模型凭借其强大的对齐方式在多领域任务上实现了零样本识别能力,而 CLIPSelf 则进一步扩展了这一能力,使其适用于像语义分割和目标检测这样的密集预测任务,达到了新的高性能。
在这篇文章中,我将首先介绍CLIP模型的基础内容,接着探讨 CLIPSelf 的核心思想、技术创新点、实现方法以及其在多个基准测试上的表现。 通过自蒸馏机制,CLIPSelf 实现了从图像级别的对比学习到像素级别的密集预测的知识转移,无需额外的监督信号,同时保持了 CLIP 模型开放词汇的优势。
这一技术对于实际应用具有重要意义,特别是在处理包含未见过类别的场景时,能够提供更加灵活和强大的视觉理解能力。
根据这篇文章,我对多模态数据融合产生了极大的兴趣,特别是CLIP这种朴素的想法,在使用大量文本-图像对齐之后,模型具有良好的模态交互能力,但是这种能力仍然受到限制,我希望未来优化多模态数据融合架构,形成像transformer一样的模型架构。
通过以下幻灯片,我将逐步解析 CLIPSelf 的工作原理和技术细节。