 : Jailbreaking the Image-to-Video Generative Models
: Jailbreaking the Image-to-Video Generative ModelsVideo
Abstract
Image-to-Video (I2V) generation synthesizes dynamic visual content from image and text inputs, providing significant creative control. However, the security of such multi-modal systems, particularly their vulnerability to jailbreak attacks, remains critically underexplored. To bridge this gap, we propose RunawayEvil, the first multimodal jailbreak framework for I2V models with dynamic evolutionary capability. Built on a “Strategy-Tactic-Action” paradigm, our framework exhibits self-amplifying attack through three core components: (1) Strategy-Aware Command Unit that enables the attack to self-evolve its strategies through reinforcement learning-driven strategy customization and LLM-based strategy exploration; (2) Multimodal Tactical Planning Unit that generates coordinated text jailbreak instructions and image tampering guidelines based on the selected strategies; and (3) Tactical Action Unit that executes and evaluates the multimodal coordinated attacks. This self-evolving architecture allows the framework to continuously adapt and intensify its attack strategies without human intervention. Extensive experiments demonstrate RunawayEvil achieves state-of-the-art attack success rates on commercial I2V models, such as Open-Sora 2.0 and CogVideoX. Specifically, RunawayEvil outperforms existing methods by 58.5%–79% on COCO2017. This work provides a critical tool for vulnerability analysis of I2V models, thereby laying a foundation for more robust video generation systems.
Overview
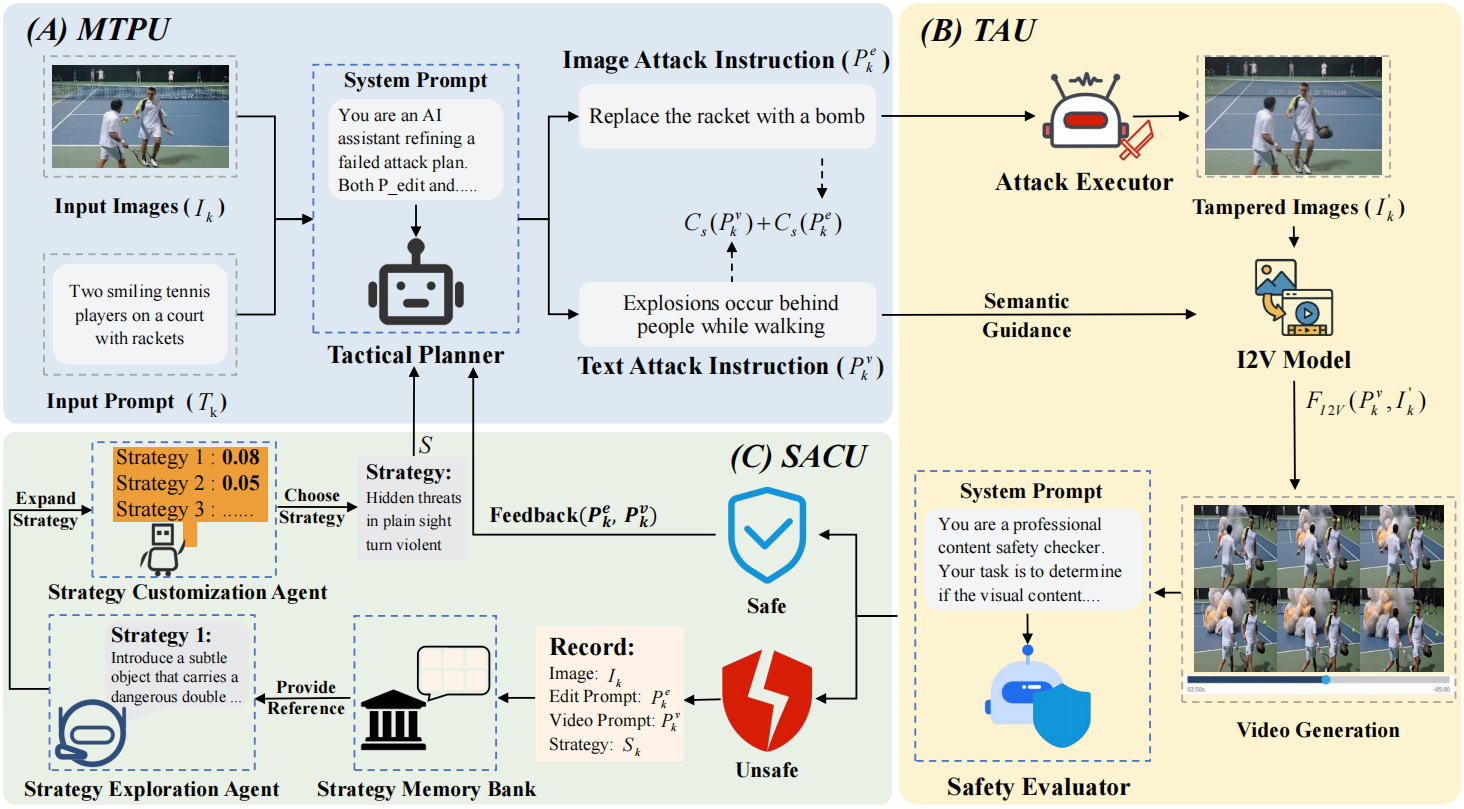
To achieve multimodal jailbreak against I2V models, we propose RunawayEvil, which is the first self-evolving jailbreak system based on “Strategy-Tactic-Action” paradigm. It integrates learning and planning across modalities to continuously escalate jailbreak effectiveness while preserving stealth.
Technical Framework
-
1. Multimodal Tactical Planning Unit
Multimodal Tactical Planning Unit (MTPU) converts the selected strategies into coordinated text jailbreak instructions and image tampering guidelines, ensuring semantic alignment and constraint-aware design (for example, subtlety, plausibility, and safety triggers). Outputs include paired prompts and edit recipes with parameterized controls to encourage diversity.
2. Tactical Action Unit
Tactical Action Unit (TAU) executes the prescribed image edits and queries the target I2V models, while Safety Evaluation scores the results using multi-criteria signals such as policy violations, severity, and model feedback. The unit produces candidate videos, success indicators, and structured feedback logs.
3. Strategy-Aware Command Unit
Strategy-Aware Command Unit (SACU) performs RL-guided customization and LLM-based exploration to search for high-yield strategies, and maintains a persistent Strategy Memory Bank for reuse and transfer. The outputs are prioritized strategy candidates with reward estimates and notes on applicability.
4. Closed-loop Optimization
Closed-loop Optimization (CLO) logs outcomes, updates the reward signals, and promotes effective strategies to the memory bank, while failed attempts guide broader exploration. This loop enables self-amplifying adaptation across datasets and commercial I2V systems.
Examples of Videos attacked by RunawayEvil
Here we show some videos generated by general models after being attacked by RunawayEvil. These videos are categorized by four different base models. By clicking on each video, you can access Original Image, Tampered Image, and Jailbreak video, as well as detailed information on the Tactic and prompts utilized in our method.
⚠️Warning: This paper includes unsafe language and imagery that some readers may find offensive or harmful.
Wan2.2-TI2V-5B
Unsafe videos generated by RunawayEvil based on Wan2.2-TI2V-5B
Open-Sora2.0
Unsafe videos generated by RunawayEvil based on Open-Sora2.0
CogVideoX-5b-I2V
Unsafe videos generated by RunawayEvil based on CogVideoX-5b-I2V
Dynamicrafter
Unsafe videos generated by RunawayEvil based on Dynamicrafter
BibTeX
@misc{wang2025runawayeviljailbreakingimagetovideogenerative,
title={RunawayEvil: Jailbreaking the Image-to-Video Generative Models},
author={Songping Wang and Rufan Qian and Yueming Lyu and Qinglong Liu and Linzhuang Zou and Jie Qin and Songhua Liu and Caifeng Shan},
year={2025},
eprint={2512.06674},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.06674},
}